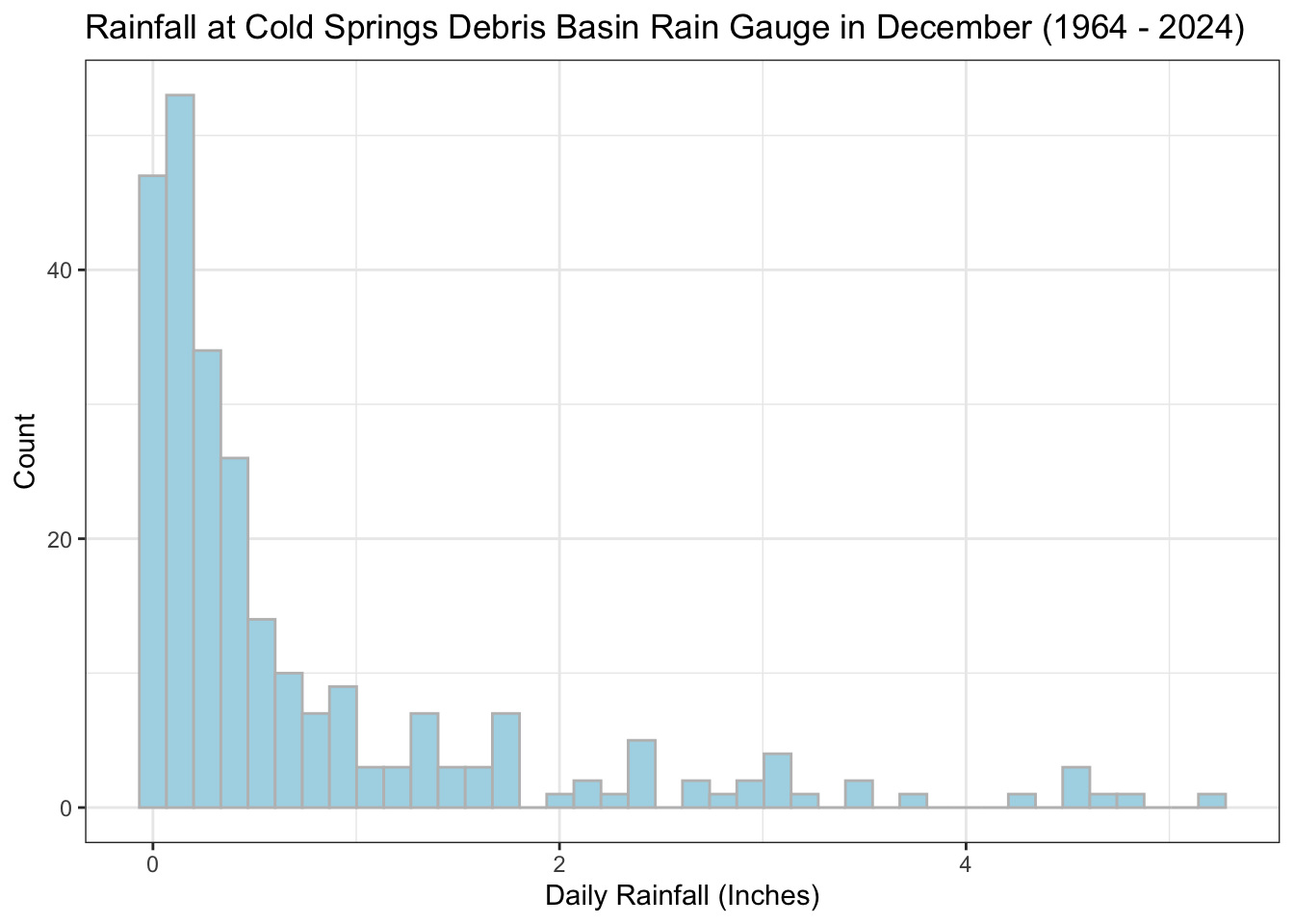
The Western monarch butterfly (Danaus plexippus) is an iconic species that was once prolific across the United States. While monarchs can be found throughout most of the US at some point during the year, the species is divided into two unofficial groups by the Continental Divide. Western monarchs are found in the western half of the United States, Eastern monarchs in the the eastern half. However, these two groups are not genetically distinct. Monarchs are a migratory species, with western monarchs spending most of the spring and summer months in Washington, Oregon, Idaho, Utah, Nevada, and Arizona. In the winter, they migrate back to Coastal California where they will spend the winter months at overwintering sites. These overwintering sites extend from Medocino County in California to Baja California in Mexico. Scientists have witnessed monarchs returning to the same overwintering sites year after year.
Overwintering Sites
So what makes up a preferred overwintering site for monarchs? Overwintering sites typically consist of a thick grove of wind-protected trees where monarchs can cluster together and be protected from the elements. Overwintering sites are typically found to be thick groves of Eucalyptus tree species or Monterey cypress (Cupressus macrocarpa). Overwintering monarchs are particularly vulnerable to swings in temperature. Temperatures need to be sufficiently low enough that monarch metabolisims are not overworked, while not being so low that they freeze.
Import Libraries and Load Data
# Load librarieslibrary(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(here)
here() starts at /Users/rachelswick/Documents/MEDS/rfswick.github.io
library(kableExtra)
Attaching package: 'kableExtra'
The following object is masked from 'package:dplyr':
group_rows
library(dynlm)
Loading required package: zoo
Attaching package: 'zoo'
The following objects are masked from 'package:base':
as.Date, as.Date.numeric
New names:
Rows: 389 Columns: 40
── Column specification
──────────────────────────────────────────────────────── Delimiter: "," chr
(10): SITE NAME, COUNTY, 2016, 2017, 2018, 2019, 2020, 2021, 2022, 2023 dbl
(1): SITE ID num (27): 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005,
2006, 2007, ... lgl (2): ...39, ...40
ℹ Use `spec()` to retrieve the full column specification for this data. ℹ
Specify the column types or set `show_col_types = FALSE` to quiet this message.
• `` -> `...39`
• `` -> `...40`
Warning: One or more parsing issues, call `problems()` on your data frame for details,
e.g.:
dat <- vroom(...)
problems(dat)
Rows: 1778 Columns: 8
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): code
dbl (6): station id, water year, year, month, day, daily rain
lgl (1): ...8
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Warning: One or more parsing issues, call `problems()` on your data frame for details,
e.g.:
dat <- vroom(...)
problems(dat)
Rows: 2249 Columns: 12
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (6): station id, water year, year, month, day, daily rain
lgl (6): code, ...8, ...9, ...10, ...11, ...12
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Rows: 2816 Columns: 7
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): code
dbl (6): station id, water year, year, month, day, daily rain
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Clean Monarch Data
# Add "y_" to beginning of year columns to select columns more easilynames(monarch_data)[4:ncol(monarch_data)] <-paste0("y_", names(monarch_data)[4:ncol(monarch_data)])# Select monarch data from Santa Barbara countymonarch_sb <- monarch_data %>%filter(COUNTY =="Santa Barbara") %>%mutate(across(starts_with("y_"), as.integer))
Warning: There were 6 warnings in `mutate()`.
The first warning was:
ℹ In argument: `across(starts_with("y_"), as.integer)`.
Caused by warning:
! NAs introduced by coercion
ℹ Run `dplyr::last_dplyr_warnings()` to see the 5 remaining warnings.
# Remove "y_" from the beginning of year columnsnames(monarch_sb) <-gsub("^y_", "", names(monarch_sb))# Make the year columns tidy and drop unneeded columnsmonarch_sb <- monarch_sb %>%pivot_longer(cols =starts_with("19") |starts_with("20"), names_to ="YEAR", values_to ="COUNT") %>%select(-starts_with("LS"), -starts_with("..."))
Select Monarch Data
# Number of NA values at each sitemonarch_sb_site <- monarch_sb %>%group_by(`SITE NAME`) %>%summarize(NA_Count =sum(is.na(COUNT)))# Total monarch count by yearmonarch_sb_total <- monarch_sb %>%group_by(YEAR) %>%summarize(Total_Count =sum(COUNT, na.rm =TRUE))# Average monarch count by yearmonarch_sb_avg_1 <- monarch_sb %>%group_by(YEAR) %>%summarize(Avg_Count =round(mean(COUNT, na.rm =TRUE), 0)) %>%rename(year = YEAR,avg_count = Avg_Count)# Average monarch count by yearmonarch_sb_avg <- monarch_sb %>%group_by(YEAR) %>%summarize(Avg_Count =round(mean(COUNT, na.rm =TRUE), 0)) %>%rename(year = YEAR,avg_count = Avg_Count)# Elwood Mesa average monarch count by yearmonarch_ellwood_avg <- monarch_sb %>%filter(str_starts(`SITE NAME`, "Ellwood")) %>%group_by(YEAR) %>%summarize(Avg_Count =round(mean(COUNT, na.rm =TRUE), 0))
Monarch Count Trends
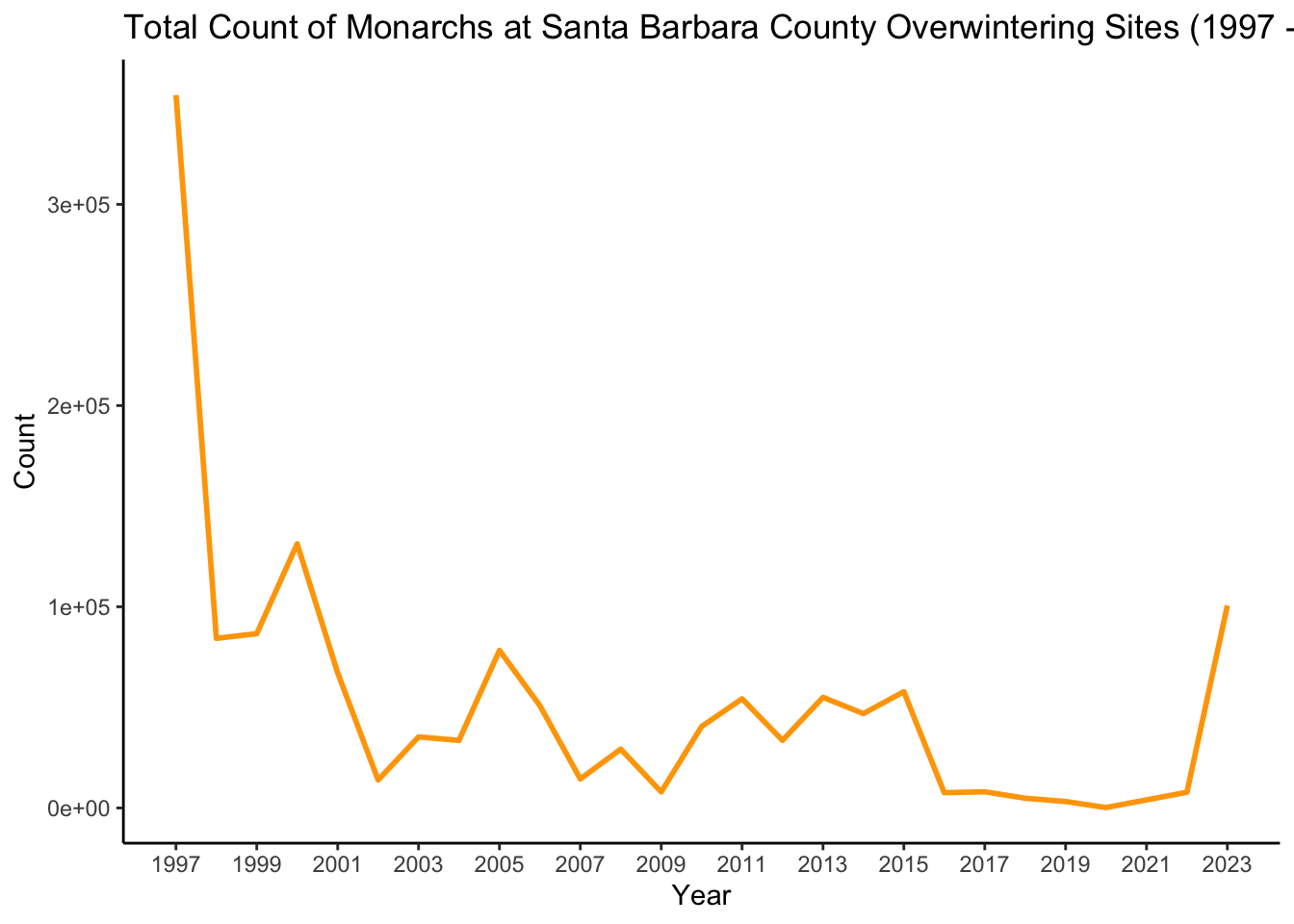
# Update year to be a date objectmonarch_sb_total$YEAR <-as.Date(paste(monarch_sb_total$YEAR, "01", "01", sep ="-"))# Plotggplot(data = monarch_sb_total, aes(x = YEAR, y = Total_Count, group =1)) +geom_line(color ="orange",lwd =1) +labs(title ="Total Count of Monarchs at Santa Barbara County Overwintering Sites (1997 - 2023)",x ="Year",y ="Count") +scale_x_date(breaks ="2 years", labels = scales::date_format("%Y")) +theme_classic()
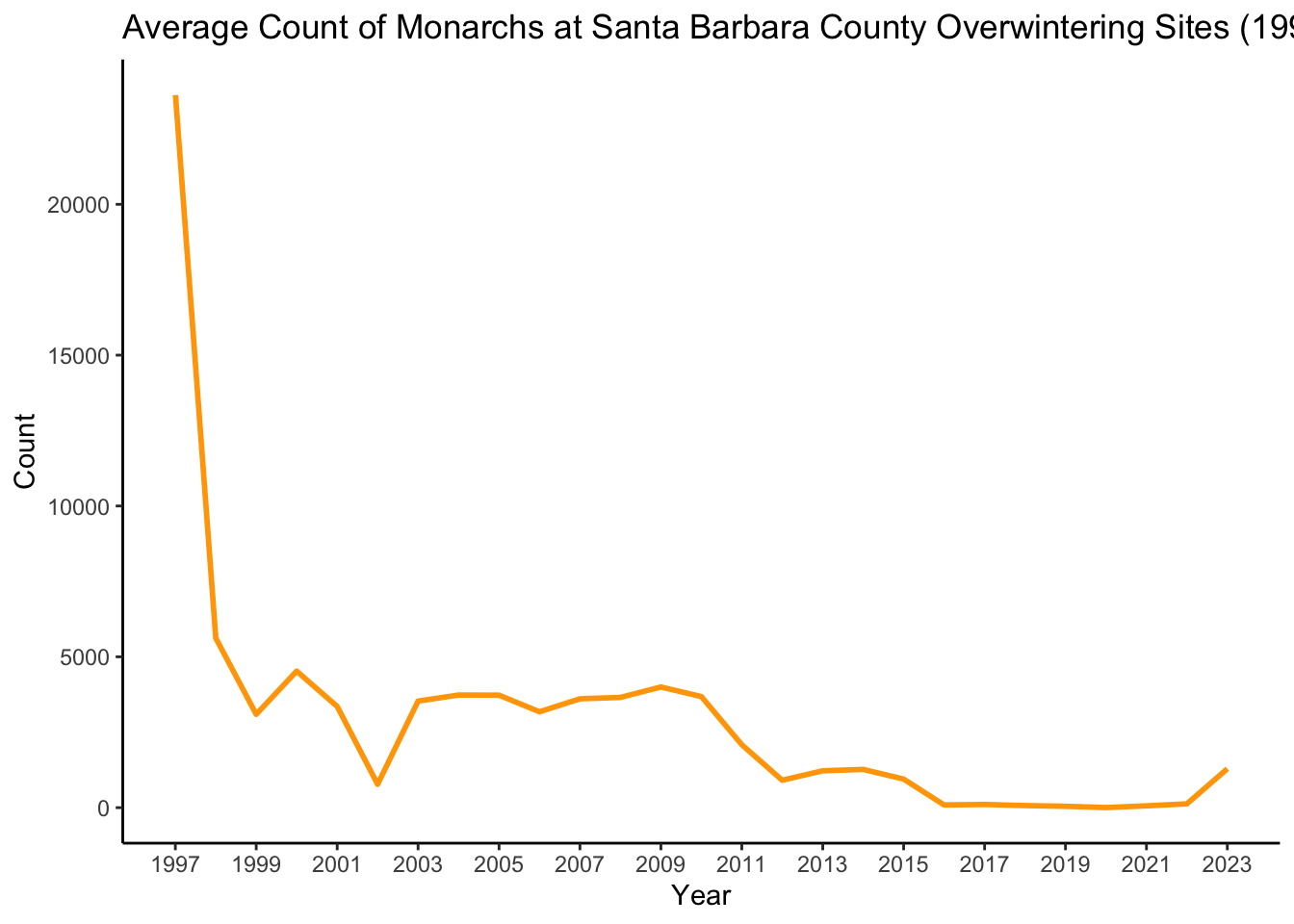
# Update year to be a date objectmonarch_sb_avg_1$year <-as.Date(paste(monarch_sb_avg_1$year, "01", "01", sep ="-"))# Plotggplot(data = monarch_sb_avg_1, aes(x = year, y = avg_count, group =1)) +geom_line(color ="orange",lwd =1) +labs(title ="Average Count of Monarchs at Santa Barbara County Overwintering Sites (1997 - 2023)",x ="Year",y ="Count") +scale_x_date(breaks ="2 years", labels = scales::date_format("%Y")) +theme_classic()
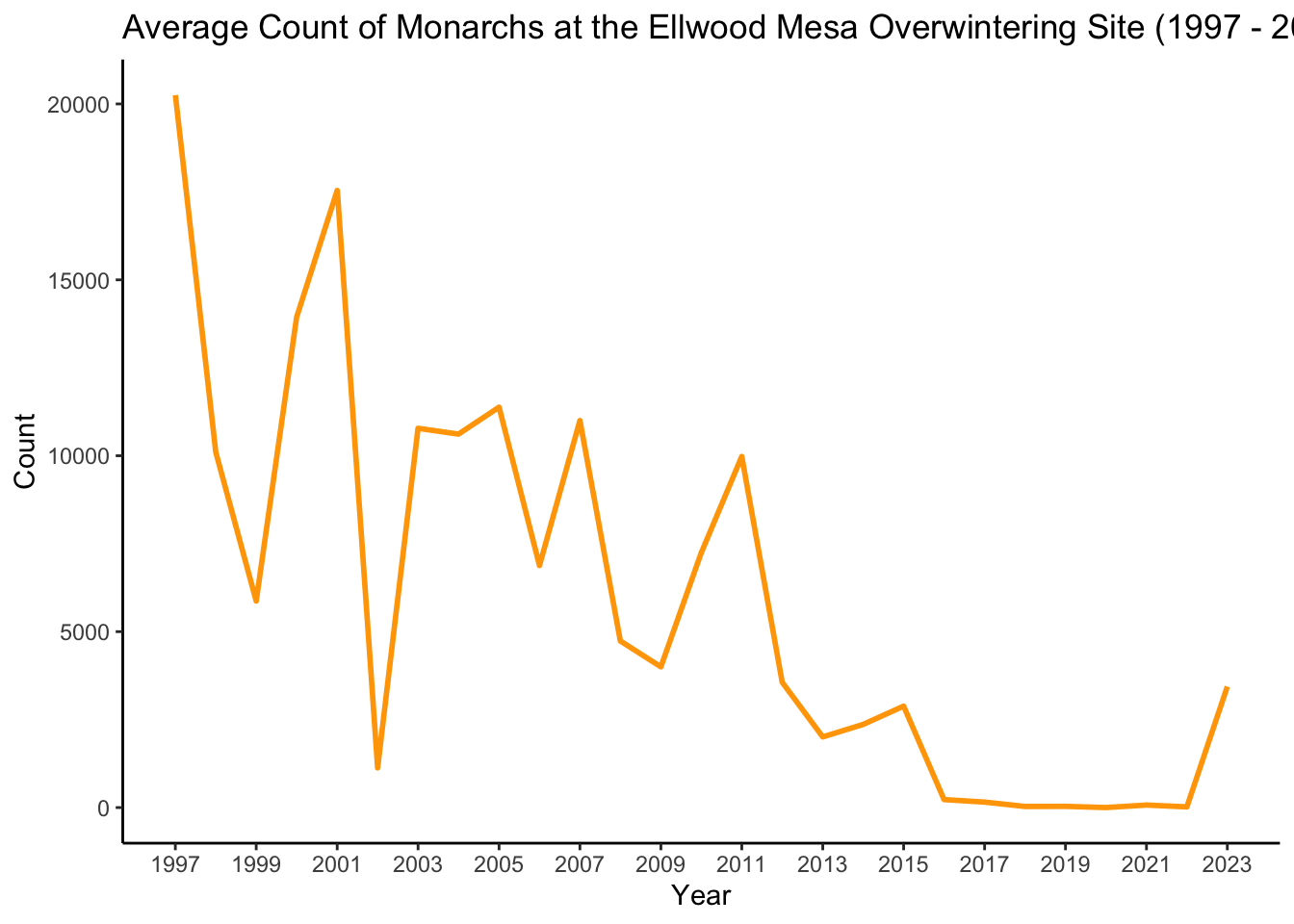
# Update year to be a date objectmonarch_ellwood_avg$YEAR <-as.Date(paste(monarch_ellwood_avg$YEAR, "01", "01", sep ="-"))# Plotggplot(data = monarch_ellwood_avg, aes(x = YEAR, y = Avg_Count, group =1)) +geom_line(color ="orange",lwd =1) +labs(title ="Average Count of Monarchs at the Ellwood Mesa Overwintering Site (1997 - 2023)",x ="Year",y ="Count") +scale_x_date(breaks ="2 years", labels = scales::date_format("%Y")) +theme_classic()
# Combine rain gauge data togetherrain_gauge_data <-bind_rows(mont_rain_grouped, goleta_rain_grouped, carp_rain_grouped, sb_rain_grouped, lompoc_rain_grouped)# Average number of storm events across all rain gaugesstorm_events <- rain_gauge_data %>%group_by(year) %>%summarize(avg_storm_events =round(mean(rain_events), 2))
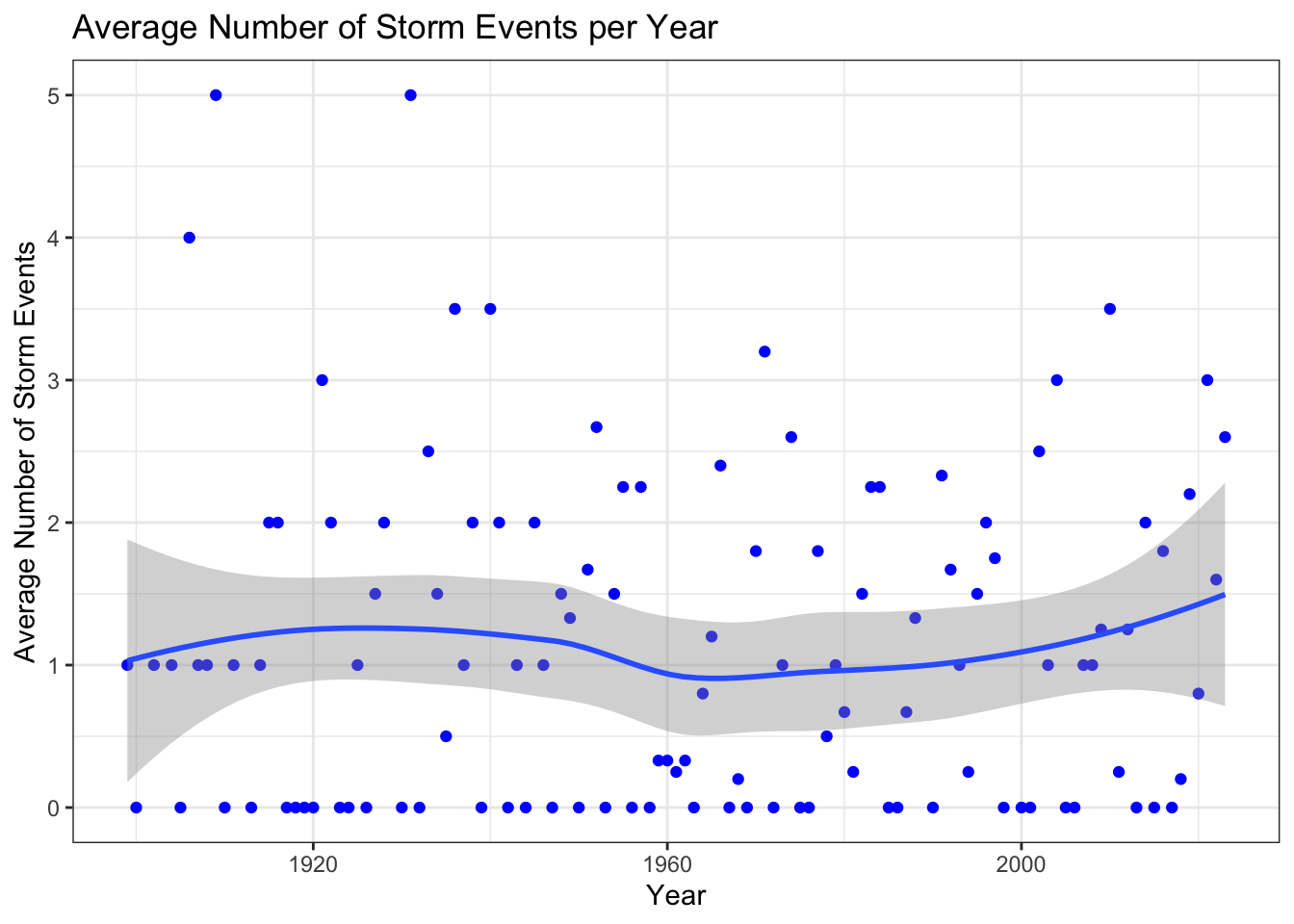
Determine if the number of storm events has been increasing over time
ggplot(storm_events, aes(x = year, y = avg_storm_events)) +geom_point(color ="blue") +geom_smooth() +labs(title ="Average Number of Storm Events per Year",x ="Year",y ="Average Number of Storm Events") +theme_bw()
`geom_smooth()` using method = 'loess' and formula = 'y ~ x'
# Determine if there is correlation between time and storm eventscor(storm_events$avg_storm_events, storm_events$year)
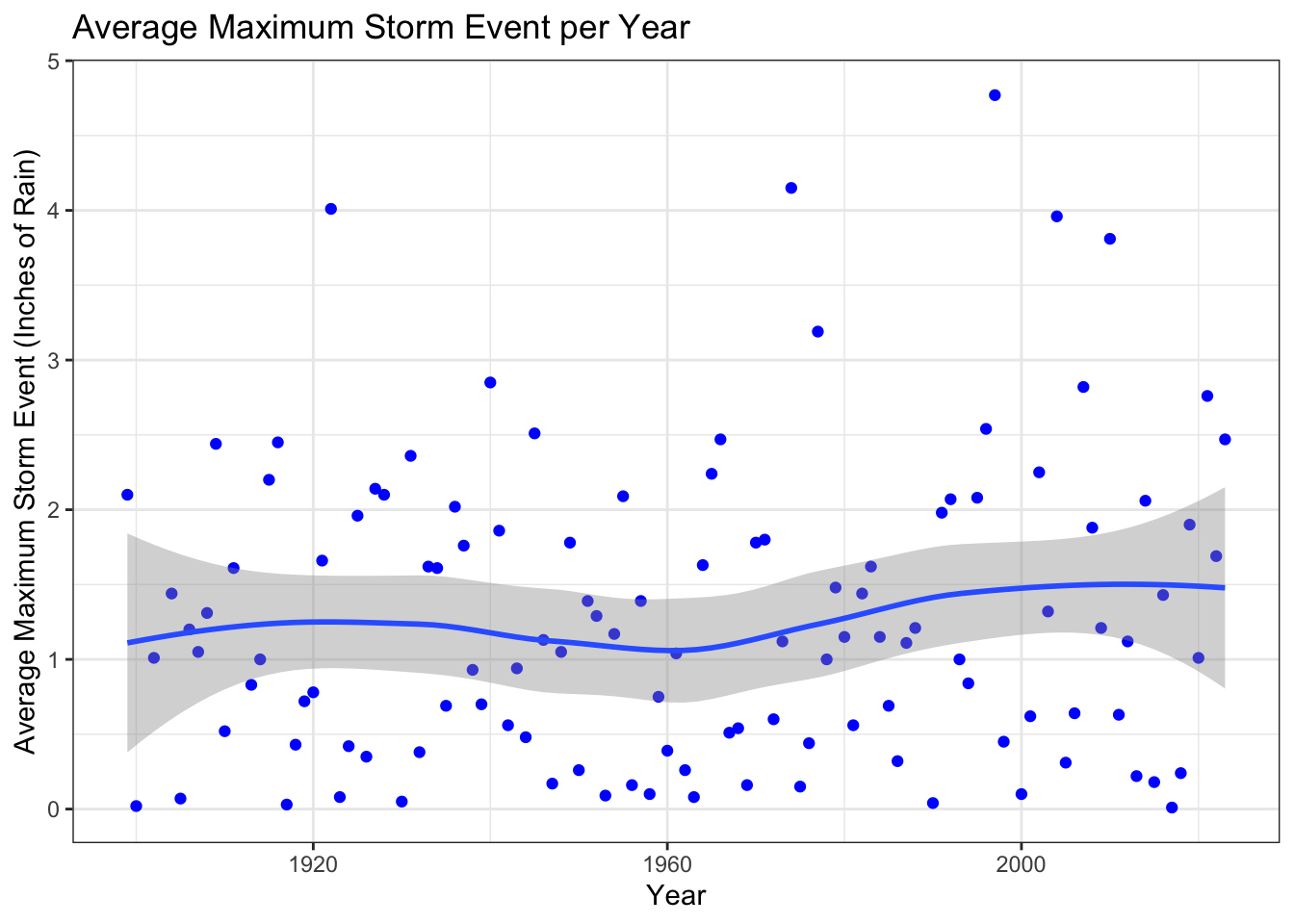
# Combine rain gauge data togetherrain_gauge_max <-bind_rows(mont_rain_max, goleta_rain_max, carp_rain_max, sb_rain_max, lompoc_rain_max)# Average number of storm events across all rain gaugesmax_storm_events <- rain_gauge_max %>%group_by(year) %>%summarize(max_storm_event =round(mean(max_storm), 2))
ggplot(max_storm_events, aes(x = year, y = max_storm_event)) +geom_point(color ="blue") +geom_smooth() +labs(title ="Average Maximum Storm Event per Year",x ="Year",y ="Average Maximum Storm Event (Inches of Rain)") +theme_bw()
`geom_smooth()` using method = 'loess' and formula = 'y ~ x'
# Determine if there is correlation between time and storm eventscor(max_storm_events$max_storm_event, max_storm_events$year)
[1] 0.1005336
Combine rain and monarch data together
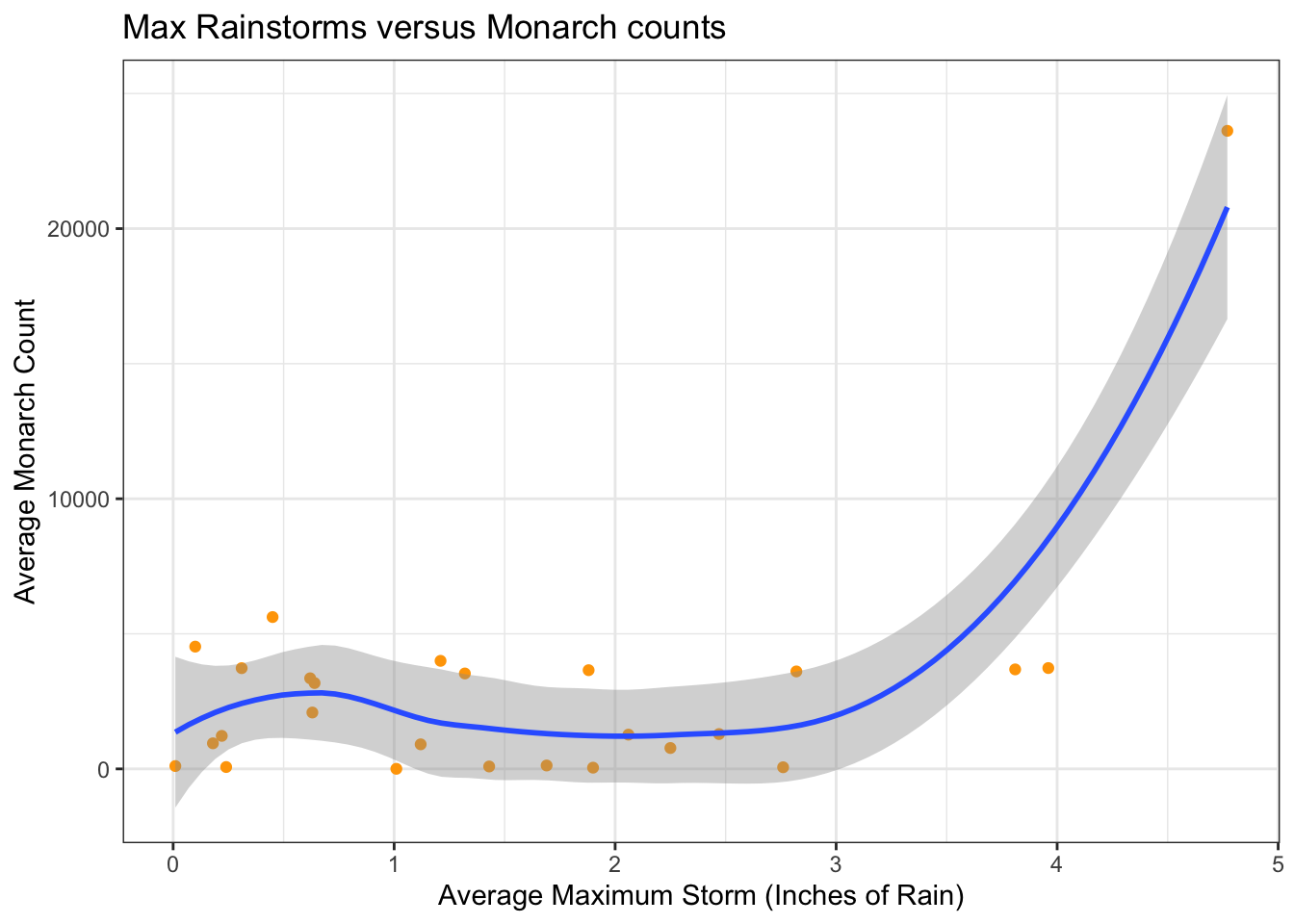
# Combine rain and monarch datamonarch_rain_df <-merge(monarch_sb_avg, max_storm_events, by ="year")monarch_rain_df <-merge(monarch_rain_df, storm_events, by ="year")
ggplot(monarch_rain_df, aes(x = max_storm_event, y = avg_count)) +geom_point(color ="orange") +geom_smooth() +labs(title ="Max Rainstorms versus Monarch counts",x ="Average Maximum Storm (Inches of Rain)",y ="Average Monarch Count") +theme_bw()
`geom_smooth()` using method = 'loess' and formula = 'y ~ x'
# Determine if there is correlation between time and storm eventscor(monarch_rain_df$max_storm_event, monarch_rain_df$avg_count)
[1] 0.4857452
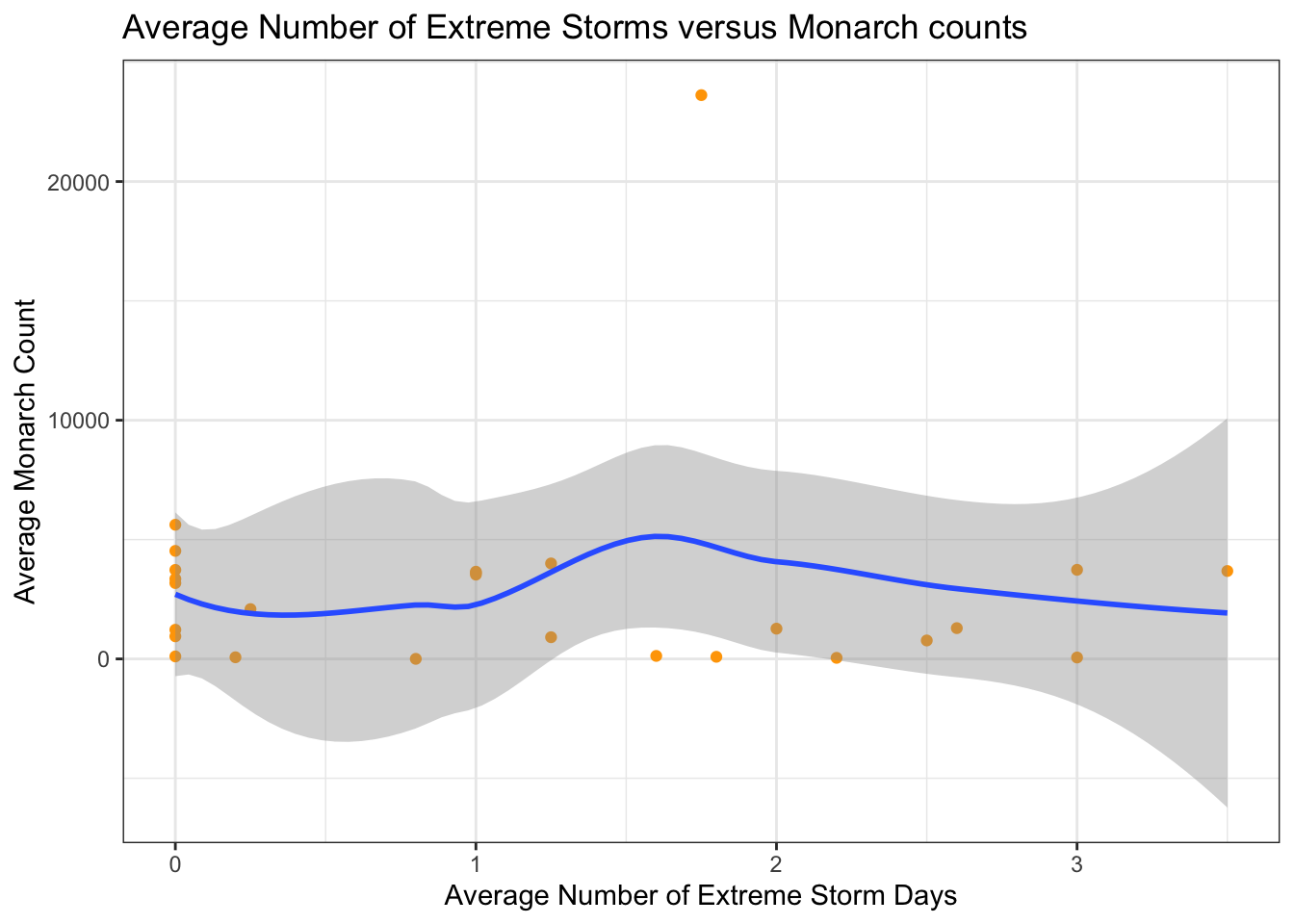
ggplot(monarch_rain_df, aes(x = avg_storm_events, y = avg_count)) +geom_point(color ="orange") +geom_smooth() +labs(title ="Average Number of Extreme Storms versus Monarch counts",x ="Average Number of Extreme Storm Days",y ="Average Monarch Count") +theme_bw()
`geom_smooth()` using method = 'loess' and formula = 'y ~ x'
# Determine if there is correlation between time and average number of storm eventscor(monarch_rain_df$avg_storm_events, monarch_rain_df$avg_count)